11 UDP Transport¶
The standard transport protocols riding above the IP layer are TCP and UDP. As we saw in Chapter 1, UDP provides simple datagram delivery to remote sockets, that is, to ⟨host,port⟩ pairs. TCP provides a much richer functionality for sending data, but requires that the remote socket first be connected. In this chapter, we start with the much-simpler UDP, including the UDP-based Trivial File Transfer Protocol.
We also review some fundamental issues any transport protocol must address, such as lost final packets and packets arriving late enough to be subject to misinterpretation upon arrival. These fundamental issues will be equally applicable to TCP connections.
11.1 User Datagram Protocol – UDP¶
RFC 1122 refers to UDP as “almost a null protocol”; while that is something of a harsh assessment, UDP is indeed fairly basic. The two features it adds beyond the IP layer are port numbers and a checksum on the data. The UDP header consists of the following:
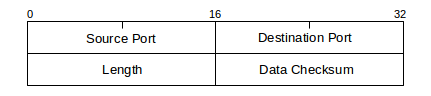
The port numbers are what makes UDP into a real transport protocol: with them, an application can now connect to an individual server process (that is, the process “owning” the port number in question), rather than simply to a host.
UDP is unreliable, in that there is no UDP-layer attempt at timeouts, acknowledgment and retransmission; applications written for UDP must implement these. As with TCP, a UDP ⟨host,port⟩ pair is known as a socket (though UDP ports are considered a separate namespace from TCP ports). UDP is also unconnected, or stateless; if an application has opened a port on a host, any other host on the Internet may deliver packets to that ⟨host,port⟩ socket without preliminary negotiation.
UDP is popular for “local” transport, confined to one LAN. In this setting it is common to use UDP as the transport basis for a Remote Procedure Call, or RPC, protocol. The conceptual idea behind RPC is that one host invokes a procedure on another host; the parameters and the return value are transported back and forth by UDP. We will consider RPC in greater detail below, in 11.7 Remote Procedure Call (RPC); for now, the point of UDP is that on a local LAN we can fall back on rather simple mechanisms for timeout and retransmission.
UDP is also popular for real-time transport; the issue here is head-of-line blocking. If a TCP packet is lost, then the receiving host queues any later data until the lost data is retransmitted successfully, which can take several RTTs; there is no option for the receiving application to request different behavior. UDP, on the other hand, gives the receiving application the freedom simply to ignore lost packets. This approach works much better for voice and video, where small losses simply degrade the received signal slightly, but where larger delays are intolerable. This is the reason the Real-time Transport Protocol, or RTP, is built on top of UDP rather than TCP. It is common for VoIP telephone calls to use RTP and UDP.
Sometimes UDP is used simply because it allows new or experimental protocols to run entirely as user-space applications; no kernel updates are required. Google has created a protocol named QUIC (Quick UDP Internet Connections) that appears to be in this category, though QUIC also takes advantage of UDP’s freedom from head-of-line blocking. QUIC’s goals include supporting multiplexed streams in a single connection (eg for the multiple components of a web page), and for eliminating the RTT needed for setting up a TCP connection. Google can achieve widespread web utilization of QUIC simply by distributing the client side in its Chrome browser; no new operating-system support (as would be required for adding a TCP mechanism) is then needed.
Finally, UDP is well-suited for “request-reply” semantics; one can use TCP to send a message and get a reply, but there is the additional overhead of setting up and tearing down a connection. DNS uses UDP, presumably for this reason. However, if there is any chance that a sequence of request-reply operations will be performed in short order then TCP may be worth the overhead.
UDP packets use the 16-bit Internet checksum (5.4 Error Detection) on the data. While it is seldom done now, the checksum can be disabled and the field set to the all-0-bits value, which never occurs as an actual ones-complement sum.
UDP packets can be dropped due to queue overflows either at an intervening router or at the receiving host. When the latter happens, it means that packets are arriving faster than the receiver can process them. Higher-level protocols typically include some form of flow control to prevent this; receiver-side ACKs often are pressed into service for this role too.
11.1.1 UDP Simplex-Talk¶
One of the early standard examples for socket programming is simplex-talk. The client side reads lines of text from the user’s terminal and sends them over the network to the server; the server then displays them on its terminal. “Simplex” here refers to the one-way nature of the flow; “duplex talk” is the basis for Instant Messaging, or IM. Even at this simple level we have some details to attend to regarding the data protocol: we assume here that the lines are sent with a trailing end-of-line marker. In a world where different OS’s use different end-of-line marks, including them in the transmitted data can be problematic. However, when we get to the TCP version, if arriving packets are queued for any reason then the embedded end-of-line character will be the only thing to separate the arriving data into lines.
As with almost every Internet protocol, the server side must select a port number, which with the server’s IP address will form the socket address to which clients connect. Clients must discover that port number or have it written into their application code. Clients too will have a port number, but it is largely invisible.
On the server side, simplex-talk must do the following:
- ask for a designated port number
- create a socket, the sending/receiving endpoint
- bind the socket to the socket address, if this is not done at the point of socket creation
- receive packets sent to the socket
- for each packet received, print its sender and its content
The client side has a similar list:
- look up the server’s IP address, using DNS
- create an “anonymous” socket; we don’t care what the client’s port number is
- read a line from the terminal, and send it to the socket address ⟨server_IP,port⟩
11.1.1.1 The Server¶
We will start with the server side, presented here in Java. We will use port 5432; the socket-creation and port-binding operations are combined into the single operation new DatagramSocket(destport). Once created, this socket will receive packets from any host that addresses a packet to it; there is no need for preliminary connection. We also need a DatagramPacket object that contains the packet data and source ⟨IP_address,port⟩ for arriving packets. The server application does not acknowledge anything sent to it, or in fact send any response at all.
The server application needs no parameters; it just starts. (That said, we could make the port number a parameter, to allow easy change. The port we use here, 5432, has also been adopted by PostgreSQL for TCP connections.) The server accepts both IPv4 and IPv6 connections; we return to this below.
Though it plays no role in the protocol, we will also have the server time out every 15 seconds and display a message, just to show how this is done; implementations of real protocols essentially always must arrange when attempting to receive a packet to time out after a certain interval with no response. The file below is at udp_stalks.java.
/* simplex-talk server, UDP version */
import java.net.*;
import java.io.*;
public class stalks {
static public int destport = 5432;
static public int bufsize = 512;
static public final int timeout = 15000; // time in milliseconds
static public void main(String args[]) {
DatagramSocket s; // UDP uses DatagramSockets
try {
s = new DatagramSocket(destport);
}
catch (SocketException se) {
System.err.println("cannot create socket with port " + destport);
return;
}
try {
s.setSoTimeout(timeout); // set timeout in milliseconds
} catch (SocketException se) {
System.err.println("socket exception: timeout not set!");
}
// create DatagramPacket object for receiving data:
DatagramPacket msg = new DatagramPacket(new byte[bufsize], bufsize);
while(true) { // read loop
try {
msg.setLength(bufsize); // max received packet size
s.receive(msg); // the actual receive operation
System.err.println("message from <" +
msg.getAddress().getHostAddress() + "," + msg.getPort() + ">");
} catch (SocketTimeoutException ste) { // receive() timed out
System.err.println("Response timed out!");
continue;
} catch (IOException ioe) { // should never happen!
System.err.println("Bad receive");
break;
}
String str = new String(msg.getData(), 0, msg.getLength());
System.out.print(str); // newline must be part of str
}
s.close();
} // end of main
}
11.1.1.2 UDP and IP addresses¶
The line s = new DatagramSocket(destport) creates a DatagramSocket object bound to the given port. If a host has multiple IP addresses, packets sent to that port to any of those IP addresses will be delivered to the socket, including localhost (and in fact all IPv4 addresses between 127.0.0.1 and 127.255.255.255) and the subnet broadcast address (eg 192.168.1.255). If a client attempts to connect to the subnet broadcast address, multiple servers may receive the packet (in this we are perhaps fortunate that the stalk server does not reply).
Alternatively, we could have used
s = new DatagramSocket(int port, InetAddress local_addr)
in which case only packets sent to the host and port through the host’s specific IP address local_addr would be delivered. It does not matter here whether IP forwarding on the host has been enabled. In the original C socket library, this binding of a port to (usually) a server socket was done with the bind() call. To allow connections via any of the host’s IP addresses, the special IP address INADDR_ANY is passed to bind().
When a host has multiple IP addresses, the standard socket library does not provide a way to find out to which these an arriving UDP packet was actually sent. Normally, however, this is not a major difficulty. If a host has only one interface on an actual network (ie not counting loopback), and only one IP address for that interface, then any remote clients must send to that interface and address. Replies (if any, which there are not with stalk) will also come from that address.
Multiple interfaces do not necessarily create an ambiguity either; the easiest such case to experiment with involves use of the loopback and Ethernet interfaces (though one would need to use an application that, unlike stalk, sends replies). If these interfaces have respective IPv4 addresses 127.0.0.1 and 192.168.1.1, and the client is run on the same machine, then connections to the server application sent to 127.0.0.1 will be answered from 127.0.0.1, and connections sent to 192.168.1.1 will be answered from 192.168.1.1. The IP layer sees these as different subnets, and fills in the IP source-address field according to the appropriate subnet. The same applies if multiple Ethernet interfaces are involved, or if a single Ethernet interface is assigned IP addresses for two different subnets, eg 192.168.1.1 and 192.168.2.1.
Life is slightly more complicated if a single interface is assigned multiple IP addresses on the same subnet, eg 192.168.1.1 and 192.168.1.2. Regardless of which address a client sends its request to, the server’s reply will generally always come from one designated address for that subnet, eg 192.168.1.1. Thus, it is possible that a legitimate UDP reply will come from a different IP address than that to which the initial request was sent.
If this behavior is not desired, one approach is to create multiple server sockets, and to bind each of the host’s network IP addresses to a different server socket.
11.1.1.3 The Client¶
Next is the Java client version udp_stalkc.java. The client – any client – must provide the name of the host to which it wishes to send; as with the port number this can be hard-coded into the application but is more commonly specified by the user. The version here uses host localhost as a default but accepts any other hostname as a command-line argument. The call to InetAddress.getByName(desthost) invokes the DNS system, which looks up name desthost and, if successful, returns an IP address. (InetAddress.getByName() also accepts addresses in numeric form, eg “127.0.0.1”, in which case DNS is not necessary.) When we create the socket we do not designate a port in the call to new DatagramSocket(); this means any port will do for the client. When we create the DatagramPacket object, the first parameter is a zero-length array as the actual data array will be provided within the loop.
A certain degree of messiness is introduced by the need to create a BufferedReader object to handle terminal input.
// simplex-talk CLIENT in java, UDP version
import java.net.*;
import java.io.*;
public class stalkc {
static public BufferedReader bin;
static public int destport = 5432;
static public int bufsize = 512;
static public void main(String args[]) {
String desthost = "localhost";
if (args.length >= 1) desthost = args[0];
bin = new BufferedReader(new InputStreamReader(System.in));
InetAddress dest;
System.err.print("Looking up address of " + desthost + "...");
try {
dest = InetAddress.getByName(desthost); // DNS query
}
catch (UnknownHostException uhe) {
System.err.println("unknown host: " + desthost);
return;
}
System.err.println(" got it!");
DatagramSocket s;
try {
s = new DatagramSocket();
}
catch(IOException ioe) {
System.err.println("socket could not be created");
return;
}
System.err.println("Our own port is " + s.getLocalPort());
DatagramPacket msg = new DatagramPacket(new byte[0], 0, dest, destport);
while (true) {
String buf;
int slen;
try {
buf = bin.readLine();
}
catch (IOException ioe) {
System.err.println("readLine() failed");
return;
}
if (buf == null) break; // user typed EOF character
buf = buf + "\n"; // append newline character
slen = buf.length();
byte[] bbuf = buf.getBytes();
msg.setData(bbuf);
msg.setLength(slen);
try {
s.send(msg);
}
catch (IOException ioe) {
System.err.println("send() failed");
return;
}
} // while
s.close();
}
}
The default value of desthost here is localhost; this is convenient when running the client and the server on the same machine, in separate terminal windows.
Like the server, the client works with both IPv4 and IPv6. The InetAddress object dest in the server code above can hold either IPv4 or IPv6 addresses; InetAddress is the base class with child classes Inet4Address and Inet6Address. If the client and server can communicate at all via IPv6 and if the value of desthost supplied to the client is an IPv6-only name, then dest will be an Inet6Address object and IPv6 will be used. For example, if the client is invoked from the command line with java stalkc ip6-localhost, and the name ip6-localhost resolves to the IPv6 loopback address ::1, the client will connect to an stalk server on the same host using IPv6 (and the loopback interface). If greater IPv4-versus-IPv6 control is desired, one can to replace the getByName() call with getAllByName(), which returns an array of all addresses (InetAddress[]) associated with the given name. One can then find the IPv6 addresses by searching this array for addresses addr for which addr instanceof Inet6Address.
Finally, here is a simple python version of the client, udp_stalkc.py.
#!/usr/bin/python3
from socket import *
from sys import argv
portnum = 5432
def talk():
rhost = "localhost"
if len(argv) > 1:
rhost = argv[1]
print("Looking up address of " + rhost + "...", end="")
try:
dest = gethostbyname(rhost)
except (GAIerror, herror) as mesg: # GAIerror: error in gethostbyname()
errno,errstr=mesg.args
print("\n ", errstr);
return;
print("got it: " + dest)
addr=(dest, portnum) # a socket address
s = socket(AF_INET, SOCK_DGRAM)
s.settimeout(1.5) # we don't actually need to set timeout here
while True:
buf = input("> ")
if len(buf) == 0: return # an empty line exits
s.sendto(bytes(buf + "\n", 'ascii'), addr)
talk()
To experiment with these on a single host, start the server in one window and one or more clients in other windows. One can then try the following:
- have two clients simultaneously running, and sending alternating messages to the same server
- invoke the client with the external IP address of the server in dotted-decimal, eg 10.0.0.3 (note that localhost is 127.0.0.1)
- run the java and python clients simultaneously, sending to the same server
- run the server on a different host (eg a virtual host or a neighboring machine)
- invoke the client with a nonexistent hostname
Note that, depending on the DNS server, the last one may not actually fail. When asked for the DNS name of a nonexistent host such as zxqzx.org, many ISPs will return the IP address of a host running a web server hosting an error/search/advertising page (usually their own). This makes some modicum of sense when attention is restricted to web searches, but is annoying if it is not, as it means non-web applications have no easy way to identify nonexistent hosts.
Simplex-talk will work if the server is on the public side of a NAT firewall. No server-side packets need to be delivered to the client! But if the other direction works, something is very wrong with the firewall.
11.2 Fundamental Transport Issues¶
As we turn to actual transport protocols, including eventually TCP, we will encounter the following standard problematic cases that must be addressed if the integrity of the data is to be ensured.
Old duplicate packets: These packets can be either internal – from an earlier point in the same connection instance – or external – from a previous instance of the connection. For the internal case, the receiver must make sure that it does not accept an earlier duplicated and delayed packet as current data (if the earlier packet was not duplicated, in most cases the transfer would not have advanced). Usually internal old duplicates are prevented by numbering the data, either by block or by byte. However, if the numbering field is allowed to wrap around, an old and a new packet may have the same number.
For the external case, the connection is closed and then reopened a short time later, using the same port numbers. (A connection is typically defined by its endpoint socket addresses; thus, we refer to “reopening” the connection even if the second instance is completely unrelated. Two separate instances of a connection between the same socket addresses are sometimes known as separate incarnations of the connection.) Somehow a delayed copy of a packet from the first instance (or incarnation) of the connection arrives while the second instance is in progress. This old duplicate must not be accepted, incorrectly, as valid data, as that would corrupt the second transfer.
Both these scenarios assume that the old duplicate was sent earlier, but was somehow delayed in transit for an extended period of time, while later packets were delivered normally. Exactly how this might occur remains unclear; perhaps the least far-fetched scenario is the following:
- A first copy of the old duplicate was sent
- A routing error occurs; the packet is stuck in a routing loop
- An alternative path between the original hosts is restored, and the packet is retransmitted successfully
- Some time later, the packet stuck in the routing loop is released, and reaches its final destination
Another scenario involves a link in the path that supplies link-layer acknowledgment: the packet was sent once across the link, the link-layer ACK was lost, and so the packet was sent again. Some mechanism is still needed to delay one of the copies.
Most solutions to the old-duplicate problem assume some cap on just how late an old duplicate can be. In practical terms, TCP officially once took this time limit to be 60 seconds, but implementations now usually take it to be 30 seconds. Other protocols often implicitly adopt the TCP limit. Once upon a time, IP routers were expected to decrement a packet’s TTL field by 1 for each second the router held the packet in its queue; in such a world, IP packets cannot be more than 255 seconds old.
It is also possible to prevent external old duplicates by including a connection count parameter in the transport or application header. For each consecutive connection, the connection count is incremented by (at least) 1. A separate connection-count value must be maintained by each side; if a connection-count value is ever lost, a suitable backup mechanism based on delay might be used. As an example, see 12.11 TCP Faster Opening.
Lost final ACK: Most packets will be acknowledged. The final packet (typically but not necessarily an ACK) cannot itself be acknowledged, as then it would not be the final packet. Somebody has to go last. This leaves some uncertainty on the part of the sender: did the last packet make it through, or not?
Duplicated connection request: How do we distinguish between two different connection requests and a single request that was retransmitted? Does it matter?
Reboots: What if one side reboots while the other side is still sending data? How will the other side detect this? Are there any scenarios that could lead to corrupted data?
11.3 Trivial File Transport Protocol, TFTP¶
As an actual protocol based on UDP, we consider the Trivial File Transport Protocol, TFTP. While TFTP supports clients sending files to the server, we will restrict attention to the more common case where the client requests a file from the server.
Although TFTP is a very simple protocol, it addresses all the fundamental transport issues listed above, to at least some degree.
TFTP, documented first in RFC 783 and updated in RFC 1350, has five packet types:
- Read ReQuest, RRQ, containing the filename and a text/binary indication
- Write ReQuest, WRQ
- Data, containing a 16-bit block number and up to 512 bytes of data
- ACK, containing a 16-bit block number
- Error, for certain designated errors. All errors other than “Unknown Transfer ID” are cause for termination.
Data block numbering begins at 1; we will denote the packet with the Nth block of data as Data[N]. Acknowledgments contain the block number of the block being acknowledged; thus, ACK[N] acknowledges Data[N]. All blocks of data contain 512 bytes except the final block, which is identified as the final block by virtue of containing less than 512 bytes of data. If the file size was divisible by 512, the final block will contain 0 bytes of data.
Because TFTP uses UDP it must take care of packetization itself, and thus must fix a block size small enough to be transmitted successfully everywhere.
In the absence of packet loss or other errors, TFTP file requests proceed as follows.
- The client sends a RRQ to server port 69, from client port c_port
- The server obtains a new port, s_port, from the OS
- The server sends Data[1] from s_port
- The client receives Data[1], and thus learns the value of s_port
- The client sends ACK[1] (and all future ACKs) to the server’s s_port
- The server sends Data[2], etc, each time waiting for the client ACK[N] before sending Data[N+1]
- The transfer process stops when the server sends its final block, of size less than 512 bytes, and the client sends the corresponding ACK
- An optional but recommended step of server-side dallying is used to address the lost-final-ACK issue
11.3.1 Port Changes¶
In the above, the server changes to a new port s_port when answering. While this change plays a modest role in the reliability of the protocol, below, it also makes the implementer’s life much easier. When the server creates the new port, it is assured that the only packets that will arrive at that port are those related to the original client request; other client requests will be associated with other server ports. The server can create a new process for this new port, and that process will be concerned with only a single transfer even if multiple parallel transfers are taking place.
If the server answered all requests from port 69, it would have to distinguish among multiple concurrent transfers by looking at the client socket address; each client transfer would have its own state information including block number, open file, and the time of the last successful packet. This considerably complicates the implementation.
This port-change rule does break TFTP when the server is on the public side of a NAT firewall. When the client sends an RRQ to port 69, the NAT firewall will now allow the server to respond from port 69. However, the server’s response from s_port is generally blocked, and so the client never receives Data[1].
11.4 TFTP Stop-and-Wait¶
TFTP uses a very straightforward implementation of stop-and-wait (6.1 Building Reliable Transport: Stop-and-Wait). Acknowledgment packets contain the block number of the data packet being acknowledged; that is, ACK[N] acknowledges Data[N].
In the original RFC 783 specification, TFTP was vulnerable to the Sorcerer’s Apprentice bug (6.1.2 Sorcerer’s Apprentice Bug). Correcting this problem was the justification for updating the protocol in RFC 1350, eleven years later. The omnibus hosts-requirements document RFC 1123 (referenced by RFC 1350) describes the necessary change this way:
Implementations MUST contain the fix for this problem: the sender (ie, the side originating the DATA packets) must never resend the current DATA packet on receipt of a duplicate ACK.
11.4.1 Lost Final ACK¶
The receiver, after receiving the final DATA packet and sending the final ACK, might exit. But if it does so, and the final ACK is lost, the sender will continue to timeout and retransmit the final DATA packet until it gives up; it will never receive confirmation that the transfer succeeded.
TFTP addresses this by recommending that the receiver enter into a DALLY state when it has sent the final ACK. In this state, it responds only to received duplicates of the final DATA packet; its response is to retransmit the final ACK. While one lost final ACK is possible, multiple such losses are unlikely; sooner or later the sender will receive the final ACK and may then exit.
The dally interval should be at least twice the sender’s timeout interval. Note that the receiver has no direct way to determine this value.
The TCP analogue of dallying is the TIMEWAIT state, though TIMEWAIT also has another role.
11.4.2 Duplicated Connection Request¶
Suppose the first RRQ is delayed. The client times out and retransmits it.
One approach would be for the server to recognize that the second RRQ is a duplicate, perhaps by noting that it is from the same client socket address and contains the same filename. In practice, however, this would significantly complicate the design of a TFTP implementation, because having the server create a new process for each RRQ that arrived would no longer be possible.
So TFTP allows the server to start two sender processes, from two ports s_port1 and s_port2. Both will send Data[1] to the receiver. The receiver is expected to “latch on” to the port of the first Data[1] packet received, recording its source port. The second Data[1] now appears to be from an incorrect port; the TFTP specification requires that a receiver reply to any packets from an unknown port by sending an ERROR packet with the code “Unknown Transfer ID” (where “Transfer ID” means “port number”). Were it not for this duplicate-RRQ scenario, packets from an unknown port could probably be simply ignored.
What this means in practice is that the first of the two sender processes above will successfully connect to the receiver, and the second will receive the “Unknown Transfer ID” message and will exit.
A more unfortunate case related to this is below, example 4 under “TFTP Scenarios”.
11.4.3 TFTP States¶
The TFTP specification is relatively informal; more recent protocols are often described using finite-state terminology. In each allowable state, the specification spells out the appropriate response to all packets.
Above we defined a DALLYING state, for the receiver only, with a specific response to arriving Data[N] packets. There are two other important conceptual states for TFTP receivers, which we might call UNLATCHED and ESTABLISHED.
When the receiver-client first sends RRQ, it does not know the port number from which the sender will send packets. We will call this state UNLATCHED, as the receiver has not “latched on” to the correct port. In this state, the receiver waits until it receives a packet from the sender that looks like a Data[1] packet; that is, it is from the sender’s IP address, it has a plausible length, it is a DATA packet, and its block number is 1. When this packet is received, the receiver records s_port, and enters the ESTABLISHED state.
Once in the ESTABLISHED state, the receiver verifies for all packets that the source port number is s_port. If a packet arrives from some other port, the receiver sends back to its source an ERROR packet with “Unknown Transfer ID”, but continues with the original transfer.
Here is an outline, in java, of what part of the TFTP receiver source code might look like; the code here handles the ESTABLISHED state. Somewhat atypically, the code here times out and retransmits ACK packets if no new data is received in the interval TIMEOUT; generally timeouts are implemented only at the TFTP sender side. Error processing is minimal, though error responses are sent in response to packets from the wrong port as described in the previous section. For most of the other error conditions checked for, there is no defined TFTP response.
The variables state, sendtime, TIMEOUT, thePacket, theAddress, thePort, blocknum and expected_block would need to have been previously declared and initialized; sendtime represents the time the most recent ACK response was sent. Several helper functions, such as getTFTPOpcode() and write_the_data(), would have to be defined. The remote port thePort would be initialized at the time of entry to the ESTABLISHED state; this is the port from which a packet must have been sent if it is to be considered valid. The loop here transitions to the DALLY state when a packet marking the end of the data has been received.
// TFTP code for ESTABLISHED state
while (state == ESTABLISHED) {
// check elapsed time
if (System.currentTimeMillis() > sendtime + TIMEOUT) {
retransmit_most_recent_ACK()
sendtime = System.currentTimeMillis()
// receive the next packet
try {
s.receive(thePacket);
}
catch (SocketTimeoutException stoe) { continue; } // try again
catch (IOException ioe) { System.exit(1); } // other errors
if (thePacket.getAddress() != theAddress) continue;
if (thePacket.getPort() != thePort) {
send_error_packet(...); // Unknown Transfer ID; see text
continue;
}
if (thePacket.getLength() < TFTP_HDR_SIZE) continue; // TFTP_HDR_SIZE = 4
opcode = thePacket.getData().getTFTPOpcode()
blocknum = thePacket.getData().getTFTPBlock()
if (opcode != DATA) continue;
if (blocknum != expected_block) continue;
write_the_data(...);
expected_block ++;
send_ACK(...); // and save it too for possible retransmission
sendtime = System.currentTimeMillis();
datasize = thePacket.getLength() - TFTP_HDR_SIZE;
if (datasize < MAX_DATA_SIZE) state = DALLY; // MAX_DATA_SIZE = 512
}
Note that the check for elapsed time is quite separate from the check for the SocketTimeoutException. It is possible for the receiver to receive a steady stream of “wrong” packets, so that it never encounters a SocketTimeoutException, and yet no “good” packet arrives and so the receiver must still arrange (as above) for a timeout and retransmission.
11.5 TFTP scenarios¶
1. Duplicated RRQ: This was addressed above. Usually two child processes will start on the server. The one that the client receives Data[1] from first is the one the client will “latch on” to; the other will be sent an ERROR packet.
2. Lost final ACK: This is addressed with the DALLYING state.
3. Old duplicate: From the same connection, this is addressed by not allowing the 16-bit sequence number to wrap around. This limits the maximum TFTP transfer to 65,535 blocks, or 32 megabytes.
For external old duplicates, involving an earlier instance of the connection, the only way this can happen is if both sides choose the same port number for both instances. If either side chooses a new port, this problem is prevented. If ports are chosen at random as in the sidebar above, the probability that both sides will chose the same ports for the subsequent connection is around 1/232; if ports are assigned by the operating system, there is an implicit assumption that the OS will not reissue the same port twice in rapid succession. Note that this issue represents a second, more fundamental and less pragmatic, reason for having the server choose a new port for each transfer.
After enough time, port numbers will eventually be recycled, but we will assume old duplicates have a limited lifetime.
4. Getting a different file than requested: Suppose the client sends RRQ(“foo”), but transmission is delayed. In the meantime, the client reboots or aborts, and then sends RRQ(“bar”). This second RRQ is lost, but the server sends Data[1] for “foo”.
At this point the client believes it is receiving file “bar”, but is in fact receiving file “foo”.
In practical terms, this scenario seems to be of limited importance, though “diskless” workstations often did use TFTP to request their boot image file when restarting.
If the sender reboots, the transfer simply halts.
5. Malicious flooding: A malicious application aware that client C is about to request a file might send repeated copies of bad Data[1] to likely ports on C. When C does request a file (eg if it requests a boot image upon starting up, from port 1024), it may receive the malicious file instead of what it asked for.
This is a consequence of the server handoff from port 69 to a new port. Because the malicious application must guess the client’s port number, this scenario too appears to be of limited importance.
11.6 TFTP Throughput¶
On a single physical Ethernet, the TFTP sender and receiver would alternate using the channel, with very little “turnaround” time; the effective throughput would be close to optimal.
As soon as the store-and-forward delays of switches and routers are introduced, though, stop-and-wait becomes a performance bottleneck. Suppose for a moment that the path from sender A to receiver B passes through two switches: A—S1—S2—B, and that on all three links only the bandwidth delay is significant. Because ACK packets are so much smaller than DATA packets, we can effectively ignore the ACK travel time from B to A.
With these assumptions, the throughput is about a third of the underlying bandwidth. This is because only one of the three links can be active at any given time; the other two must be idle. We could improve throughput threefold by allowing A to send three packets at a time:
- packet 1 from A to S1
- packet 2 from A to S1 while packet 1 goes from S1 to S2
- packet 3 from A to S1 while packet 2 goes from S1 to S2 and packet 1 goes from S2 to B
This amounts to sliding windows with a winsize of three. TFTP does not support this; in the next chapter we study TCP, which does.
11.7 Remote Procedure Call (RPC)¶
A very different communications model, usually but not always implemented over UDP, is that of Remote Procedure Call, or RPC. The name comes from the idea that a procedure call is being made over the network; host A packages up a request, with parameters, and sends it to host B, which returns a reply. The term request/reply protocol is also used for this. The side making the request is known as the client, and the other side the server.
One common example is that of DNS: a host sends a DNS lookup request to its DNS server, and receives a reply. Other examples include password verification, system information retrieval, database queries and file I/O (below). RPC is also quite successful as the mechanism for interprocess communication within CPU clusters, perhaps its most time-sensitive application.
While TCP can be used for processes like these, this adds the overhead of creating and tearing down a connection; in many cases, the RPC exchange consists of nothing further beyond the request and reply and so the TCP overhead would be nontrivial. RPC over UDP is particularly well suited for transactions where both endpoints are quite likely on the same LAN, or are otherwise situated so that losses due to congestion are negligible.
The drawback to UDP is that the RPC layer must then supply its own acknowledgment protocol. This is not terribly difficult; usually the reply serves to acknowledge the request, and all that is needed is another ACK after that. If the protocol is run over a LAN, it is reasonable to use a static timeout period, perhaps somewhere in the range of 0.5 to 1.0 seconds.
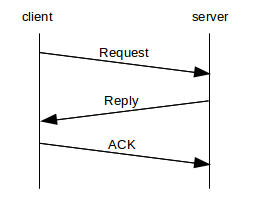
Nonetheless, there are some niceties that early RPC implementations sometimes ignored, leading to a complicated history; see 11.7.2 Sun RPC below.
It is essential that requests and replies be numbered (or otherwise identified), so that the client can determine which reply matches which request. This also means that the reply can serve to acknowledge the request; if reply[N] is not received; the requester retransmits request[N]. This can happen either if request[N] never arrived, or if it was reply[N] that got lost:
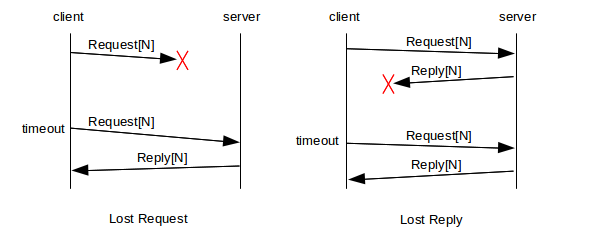
When the server creates reply[N] and sends it to the client, it must also keep a cached copy of the reply, until such time as ACK[N] is received.
After sending reply[N], the server may receive ACK[N], indicating all is well, or may receive request[N] again, indicating that reply[N] was lost, or may experience a timeout, indicating that either reply[N] or ACK[N] was lost. In the latter two cases, the server should retransmit reply[N] and wait again for ACK[N].
11.7.1 Network File Sharing¶
In terms of total packet volume, the application making the greatest use of early RPC was Sun’s Network File Sharing, or NFS; this allowed for a filesystem on the server to be made available to clients. When the client opened a file, the server would send back a file handle that typically included the file’s identifying “inode” number. For read() operations, the request would contain the block number for the data to be read, and the corresponding reply would contain the data itself; blocks were generally 8 KB in size. For write() operations, the request would contain the block of data to be written together with the block number; the reply would contain an acknowledgment that it was received.
Usually an 8 KB block of data would be sent as a single UDP/IP packet, using IP fragmentation for transmission over Ethernet.
11.7.2 Sun RPC¶
The original simple model above is quite serviceable. However, in the RPC implementation developed by Sun Microsystems and documented in RFC 1831 (and officially known as Open Network Computing, or ONC, RPC), the final acknowledgment was omitted. As there are relatively few packet losses on a LAN, this was not quite as serious as it might sound, but it did have a major consequence: the server could now not afford to cache replies, as it would never receive an indication that it was ok to delete them. Therefore, the request was re-executed upon receipt of a second request[N], as in the right-hand “lost reply” diagram above.
This was often described as at-least-once semantics: if a client sent a request, and eventually received a reply, the client could be sure that the request was executed at least once, but if a reply got lost then the request might be transmitted more than once. Applications, therefore, had to be aware that this was a possibility.
It turned out that for many requests, duplicate execution was not a problem. A request that has the same result (and same side effects on the server) whether executed once or executed twice is known as idempotent. While a request to read or write the next block of a file is not idempotent, a request to read or write block 37 (or any other specific block) is idempotent. Most data queries are also idempotent; a second query simply returns the same data as the first. Even file open() operations are idempotent, or at least can be implemented as such: if a file is opened the second time, the file handle is simply returned a second time.
Alas, there do exist fundamentally non-idempotent operations. File locking is one, or any form of exclusive file open. Creating a directory is another, because the operation must fail if the directory already exists. Even opening a file is not idempotent if the server is expected to keep track of how many open() operations have been called, in order to determine if a file is still in use.
So why did Sun RPC take this route? One major advantage of at-least-once semantics is that it allowed the server to be stateless. The server would not need to maintain any RPC state, because without the final ACK there is no server RPC state to be maintained; for idempotent operations the server would generally not have to maintain any application state either. The practical consequence of this was that a server could crash and, because there was no state to be lost, could pick up right where it left off upon restarting.
The lack of file-locking and other non-idempotent I/O operations, along with the rise of cheap client-workstation storage (and, for that matter, more-reliable servers), eventually led to the decline of NFS over RPC, though it has not disappeared. NFS can, if desired, also be run (statefully!) over TCP.
11.7.3 Serialization¶
In some RPC systems, even those with explicit ACKs, requests are executed serially by the server. Serial execution is automatic if request[N+1] serves as an implicit ACK[N]. This is a problem for file I/O operations, as physical disk drives are generally most efficient when the I/O operations can be reordered to suit the geometry of the disk. Disk drives commonly use the elevator algorithm to process requests: the read head moves from low-numbered tracks outwards to high-numbered tracks, pausing at each track for which there is an I/O request. Waiting for the Nth read to complete before asking the disk to start the N+1th one is slow.
The best solution here is to allow multiple outstanding requests and out-of-order replies.
11.7.4 Refinements¶
One basic network-level improvement to RPC concerns the avoidance of IP-level fragmentation. While fragmentation is not a major performance problem on a single LAN, it may have difficulties over longer distances. One possible refinement is an RPC-level large-message protocol, that fragments at the RPC layer and which supports a mechanism for retransmission, if necessary, only of those fragments that are actually lost.
Another optimization might address the possibility that the server reboots. If a client really wants to be sure that its request is executed only once, it needs to be sure that the server did not reboot between the original request and the client’s retransmission following a timeout. One way to achieve this is for the server to maintain a “reboot counter”, written to the disk and incremented after each restart, and then to include the value of the reboot counter in each reply. Requests contain the client’s expected value for the server reboot counter; if at the server end there is not a match, the client is notified of the potential error. Full recovery from what may have been a partially executed request, however, requires some form of application-layer “journal log” like that used for database servers.
11.8 Epilog¶
UDP does not get as much attention as TCP, but between avoidance of connection-setup overhead, avoidance of head-of-line blocking and high LAN performance, it holds its own.
We also use UDP here to illustrate fundamental transport issues, both abstractly and for the specific protocol TFTP. We will revisit these fundamental issues extensively in the next chapter in the context of TCP; these issues played a major role in TCP’s design.
11.9 Exercises¶
1. Perform the UDP simplex-talk experiments discussed at the end of 11.1.1 UDP Simplex-Talk. Can multiple clients have simultaneous sessions with the same server?
2. What would happen in TFTP if both sides implemented retransmit-on-timeout and neither side implemented retransmit-on-duplicate? Assume the actual transfer time is negligible. Assume Data[3] is sent but the first instance is lost. Consider these cases:
- sender timeout = receiver timeout = 2 seconds
- sender timeout = 1 second, receiver timeout = 3 seconds
- sender timeout = 3 seconds, receiver timeout = 1 second
3. In the previous problem, how do things change if ACK[3] is the packet that is lost?
4. Spell out plausible responses for a TFTP receiver upon receipt of a Data[N] packet for each of the states UNLATCHED, ESTABLISHED, and DALLYING. Your answer may depend on N.
Example: upon receipt of an ERROR packet, TFTP would in all three states exit.
5. In the TFTP-receiver code in 11.4.3 TFTP States, explain why we must check thePacket.getLength() before extracting the opcode and block number.
6. Outline a TFTP scenario in which the TFTP receiver of 11.4.3 TFTP States sets a socket timeout interval but never encounters a “hard” timeout – that is, a SocketTimeoutException – and yet must timeout and retransmit. Hint: the only way to avoid a hard timeout is constantly to receive some packet before the timeout timer expires.
7. In 11.5 TFTP scenarios, under “Old duplicate”, we claimed that if either side changed ports, the old-duplicate problem would not occur.
8. In the simple RPC protocol at the beginning of 11.7 Remote Procedure Call (RPC), suppose that the server sends reply[N] and experiences a timeout, receiving nothing back from the client. In the text we suggested that most likely this meant ACK[N] was lost. Give another loss scenario, involving the loss of two packets. Assume the client and the server have the same timeout interval.
9. Suppose a Sun RPC read() request ends up executing twice. Unfortunately, in between successive read() operations the block of data is updated by another process, so different data is returned. Is this a failure of idempotence? Why or why not?
10. Outline an RPC protocol in which multiple requests can be outstanding, and replies can be sent in any order. Assume that requests are numbered, and that ACK[N] acknowledges reply[N]. Can ACKs be cumulative? If not, what should happen if an ACK is lost?