1 An Overview of Networks¶
Somewhere there might be a field of interest in which the order of presentation of topics is well agreed upon.
Computer networking is not it.
There are many interconnections in the field of networking, as in most technical fields, and it is difficult to find an order of presentation that does not involve endless “forward references” to future chapters; this is true even if – as is done here – a largely bottom-up ordering is followed. I have therefore taken here a different approach: this first chapter is a summary of the essentials – LANs, IP and TCP – across the board, and later chapters expand on the material here.
Local Area Networks, or LANs, are the “physical” networks that provide the connection between machines within, say, a home, school or corporation. LANs are, as the name says, “local”; it is the IP, or Internet Protocol, layer that provides an abstraction for connecting multiple LANs into, well, the Internet. Finally, TCP deals with transport and connections and actually sending user data.
This chapter also contains some important other material. The section on datagram forwarding, central to packet-based switching and routing, is essential. This chapter also discusses packets generally, congestion, and sliding windows, but those topics are revisited in later chapters. Firewalls and network address translation are also covered here and not elsewhere.
1.1 Layers¶
These three topics – LANs, IP and TCP – are often called layers; they constitute the Link layer, the Internetwork layer, and the Transport layer respectively. Together with the Application layer (the software you use), these form the “four-layer model” for networks. A layer, in this context, corresponds strongly to the idea of a programming interface or library (though some of the layers are not accessible to ordinary users): an application hands off a chunk of data to the TCP library, which in turn makes calls to the IP library, which in turn calls the LAN layer for actual delivery.
The LAN layer is often conceptually subdivided into the “Physical layer” dealing with, eg, the electrical signaling mechanisms involved, and above that an abstracted “Logical link layer” that describes how packets can be addressed from one LAN node to another. The physical layer is generally of direct concern only to those designing LAN hardware; the kernel software interface to the LAN corresponds to the logical link layer. This LAN physical/logical division gives us the Internet five-layer model. This is less a formal hierarchy as an ad hoc classification method. We will return to this below in 1.15 IETF and OSI.
1.2 Bandwidth and Throughput¶
Any one network connection – eg at the LAN layer – has a data rate: the rate at which bits are transmitted. In some LANs (eg Wi-Fi) the data rate can vary with time. Throughput refers to the overall effective transmission rate, taking into account things like transmission overhead, protocol inefficiencies and perhaps even competing traffic. It is generally measured at a higher network layer than the data rate.
The term bandwidth can be used to refer to either of these, though we here try to use it mostly as a synonym for data rate. The term comes from radio transmission, where the width of the frequency band available is proportional, all else being equal, to the data rate that can be achieved.
In discussions about TCP, the term goodput is sometimes used to refer to what might also be called “application-layer throughput”: the amount of usable data delivered to the receiving application. Specifically, retransmitted data is counted only once when calculating goodput but might be counted twice under some interpretations of “throughput”.
Data rates are generally measured in kilobits per second (Kbps) or megabits per second (Mbps); in the context of data rates, a kilobit is 103 bits (not 210) and a megabit is 106 bits. The use of the lowercase “b” means bits; data rates expressed in terms of bytes often use an upper-case “B”.
1.3 Packets¶
Packets are modest-sized buffers of data, transmitted as a unit through some shared set of links. Of necessity, packets need to be prefixed with a header containing delivery information. In the common case known as datagram forwarding, the header contains a destination address; headers in networks using so-called virtual-circuit forwarding contain instead an identifier for the connection. Almost all networking today (and for the past 50 years) is packet-based, although we will later look briefly at some “circuit-switched” options for voice telephony.

At the LAN layer, packets can be viewed as the imposition of a buffer (and addressing) structure on top of low-level serial lines; additional layers then impose additional structure. Informally, packets are often referred to as frames at the LAN layer, and as segments at the Transport layer.
The maximum packet size supported by a given LAN (eg Ethernet, Token Ring or ATM) is an intrinsic attribute of that LAN. Ethernet allows a maximum of 1500 bytes of data. By comparison, TCP/IP packets originally often held only 512 bytes of data, while early Token Ring packets could contain up to 4KB of data. While there are proponents of very large packet sizes, larger even than 64KB, at the other extreme the ATM (Asynchronous Transfer Mode) protocol uses 48 bytes of data per packet, and there are good reasons for believing in modest packet sizes.
One potential issue is how to forward packets from a large-packet LAN to (or through) a small-packet LAN; in later chapters we will look at how the IP (or Internet Protocol) layer addresses this.
Generally each layer adds its own header. Ethernet headers are typically 14 bytes, IP headers 20 bytes, and TCP headers 20 bytes. If a TCP connection sends 512 bytes of data per packet, then the headers amount to 10% of the total, a not-unreasonable overhead. For one common Voice-over-IP option, packets contain 160 bytes of data and 54 bytes of headers, making the header about 25% of the total. Compressing the 160 bytes of audio, however, may bring the data portion down to 20 bytes, meaning that the headers are now 73% of the total; see 18.11.4 RTP and VoIP.
In datagram-forwarding networks the appropriate header will contain the address of the destination and perhaps other delivery information. Internal nodes of the network called routers or switches will then make sure that the packet is delivered to the requested destination.
The concept of packets and packet switching was first introduced by Paul Baran in 1962 ([PB62]). Baran’s primary concern was with network survivability in the event of node failure; existing centrally switched protocols were vulnerable to central failure. In 1964, Donald Davies independently developed many of the same concepts; it was Davies who coined the term “packet”.
It is perhaps worth noting that packets are buffers built of 8-bit bytes, and all hardware today agrees what a byte is (hardware agrees by convention on the order in which the bits of a byte are to be transmitted). 8-bit bytes are universal now, but it was not always so. Perhaps the last great non-byte-oriented hardware platform, which did indeed overlap with the Internet era broadly construed, was the DEC-10, which had a 36-bit word size; a word could hold five 7-bit ASCII characters. The early Internet specifications introduced the term octet (an 8-bit byte) and required that packets be sequences of octets; non-octet-oriented hosts had to be able to convert. Thus was chaos averted. Note that there are still byte-oriented data issues; as one example, binary integers can be represented as a sequence of bytes in either big-endian or little-endian byte order. RFC 1700 specifies that Internet protocols use big-endian byte order, therefore sometimes called network byte order.
1.4 Datagram Forwarding¶
In the datagram-forwarding model of packet delivery, packet headers contain a destination address. It is up to the intervening switches or routers to look at this address and get the packet to the correct destination.
In the diagram below, switch S1 has interfaces 0, 1 and 2, and S2 has interfaces 0,1,2,3. If A is to send a packet P to B, S1 must know that P must be forwarded out interface 2 and S2 must know P must be forwarded out interface 3. In datagram forwarding this is achieved by providing each switch with a forwarding table of ⟨destination,next_hop⟩ pairs. When a packet arrives, the switch looks up the destination address (presumed globally unique) in this table, and finds the next_hop information: the address to which or interface by which the packet should be forwarded in order to bring it one step closer to its final destination. In the network below, a complete forwarding table for S1 (using interface numbers as next_hop values) would be:
| S1 | |
|---|---|
| destination | next_hop |
| A | 0 |
| C | 1 |
| B | 2 |
| D | 2 |
| E | 2 |

The table for S2 might be as follows, where we have consolidated destinations A and C for visual simplicity.
| S2 | |
|---|---|
| destination | next_hop |
| A,C | 0 |
| D | 1 |
| E | 2 |
| B | 3 |
Alternatively, we could replace the interface information with next-node, or neighbor, information, as all the links above are point-to-point and so each interface connects to a unique neighbor. In that case, S1’s table might be written as follows (with consolidation of the entries for B, D and E):
| S1 | |
|---|---|
| destination | next_hop |
| A | A |
| C | C |
| B,D,E | S2 |
A central feature of datagram forwarding is that each packet is forwarded “in isolation”; the switches involved do not have any awareness of any higher-layer logical connections established between endpoints. This is also called stateless forwarding, in that the forwarding tables have no per-connection state. RFC 1122 put it this way (in the context of IP-layer datagram forwarding):
To improve robustness of the communication system, gateways are designed to be stateless, forwarding each IP datagram independently of other datagrams. As a result, redundant paths can be exploited to provide robust service in spite of failures of intervening gateways and networks.
Datagram forwarding is sometimes allowed to use other information beyond the destination address. In theory, IP routing can be done based on the destination address and some quality-of-service information, allowing, for example, different routing to the same destination for high-bandwidth bulk traffic and for low-latency real-time traffic. In practice, many ISPs ignore quality-of-service information in the IP header, and route only based on the destination.
By convention, switching devices acting at the LAN layer and forwarding packets based on the LAN address are called switches (or, in earlier days, bridges), while such devices acting at the IP layer and forwarding on the IP address are called routers. Datagram forwarding is used both by Ethernet switches and by IP routers, though the destinations in Ethernet forwarding tables are individual nodes while the destinations in IP routers are entire networks (that is, sets of nodes).
In IP routers within end-user sites it is common for a forwarding table to include a catchall default entry, matching any IP address that is nonlocal and so needs to be routed out into the Internet at large. Unlike the consolidated entries for B, D and E in the table above for S1, which likely would have to be implemented as actual separate entries, a default entry is a single record representing where to forward the packet if no other destination match is found. Here is a forwarding table for S1, above, with a default entry replacing the last three entries:
| S1 | |
|---|---|
| destination | next_hop |
| A | 0 |
| C | 1 |
| default | 2 |
Default entries make sense only when we can tell by looking at an address that it does not represent a nearby node. This is common in IP networks because an IP address encodes the destination network, and routers generally know all the local networks. It is however rare in Ethernets, because there is generally no correlation between Ethernet addresses and locality. If S1 above were an Ethernet switch, and it had some means of knowing that interfaces 0 and 1 connected directly to individual hosts, not switches – and S1 knew the addresses of these hosts – then making interface 2 a default route would make sense. In practice, however, Ethernet switches do not know what kind of device connects to a given interface.
1.5 Topology¶
In the network diagrammed in the previous section, there are no loops; graph theorists might describe this by saying the network graph is acyclic, or is a tree. In a loop-free network there is a unique path between any pair of nodes. The forwarding-table algorithm has only to make sure that every destination appears in the forwarding tables; the issue of choosing between alternative paths does not arise.
However, if there are no loops then there is no redundancy: any broken link will result in partitioning the network into two pieces that cannot communicate. All else being equal (which it is not, but never mind for now), redundancy is a good thing. However, once we start including redundancy, we have to make decisions among the multiple paths to a destination. Consider, for a moment, the following network:

Should S1 list S2 or S3 as the next_hop to B? Both paths A─S1─S2─S4─B and A─S1─S3─S4─B get there. There is no right answer. Even if one path is “faster” than the other, taking the slower path is not exactly wrong (especially if the slower path is, say, less expensive). Some sort of protocol must exist to provide a mechanism by which S1 can make the choice (though this mechanism might be as simple as choosing to route via the first path discovered to the given destination). We also want protocols to make sure that, if S1 reaches B via S2 and the S2─S4 link fails, then S1 will switch over to the still-working S1─S3─S4─B route.
As we shall see, many LANs (in particular Ethernet) prefer “tree” networks with no redundancy, while IP has complex protocols in support of redundancy.
1.6 Routing Loops¶
A potential drawback to datagram forwarding is the possibility of a routing loop: a set of entries in the forwarding tables that cause some packets to circulate endlessly. For example, in the previous picture we would have a routing loop if, for (nonexistent) destination C, S1 forwarded to S2, S2 forwarded to S4, S4 forwarded to S3, and S3 forwarded to S1. A packet sent to C would not only not be delivered, but in circling endlessly it might easily consume a large majority of the bandwidth. Routing loops typically arise because the creation of the forwarding tables is often “distributed”, and there is no global authority to detect inconsistencies. Even when there is such an authority, temporary routing loops can be created due to notification delays.
Routing loops can also occur in networks where the underlying link topology is loop-free; for example, in the previous diagram we could, again for destination C, have S1 forward to S2 and S2 forward back to S1. We will refer to such a case as a linear routing loop.
All datagram-forwarding protocols need some way of detecting and avoiding routing loops. Ethernet, for example, avoids nonlinear routing loops by disallowing loops in the underlying network topology, and avoids linear routing loops by not having switches forward a packet back out the interface by which it arrived. IP provides for a one-byte “Time to Live” (TTL) field in the IP header; it is set by the sender and decremented by 1 at each router; a packet is discarded if its TTL reaches 0. This limits the number of times a wayward packet can be forwarded to the initial TTL value, typically 64.
In datagram routing, a switch is responsible only for the next hop to the ultimate destination; if a switch has a complete path in mind, there is no guarantee that the next_hop switch or any other downstream switch to agree to forward along that path. Misunderstandings can potentially lead to routing loops. Consider this network:
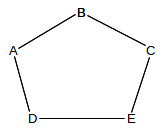
D might feel that the best path to B is D–E–C–B (perhaps because it believes the A–D link is to be avoided). If E similarly decides the best path to B is E–D–A–B, and if D and E both choose their next_hop for B based on these best paths, then a linear routing loop is formed: D routes to B via E and E routes to B via D. Although each of D and E have identified a usable path, that path is not in fact followed. Moral: successful datagram routing requires cooperation and a consistent view of the network.
1.7 Congestion¶
Switches introduce the possibility of congestion: packets arriving faster than they can be sent out. This can happen with just two interfaces, if the inbound interface has a higher bandwidth than the outbound interface; another common source of congestion is traffic arriving on multiple inputs and all destined for the same output.
Whatever the reason, if packets are arriving for a given outbound interface faster than they can be sent, a queue will form for that interface. Once that queue is full, packets will be dropped. The most common strategy (though not the only one) is to drop any packets that arrive when the queue is full.
The term “congestion” may refer either to the point where the queue is just beginning to build up, or to the point where the queue is full and packets are lost. In their paper [CJ89], Chiu and Jain refer to the first point as the knee; this is where the slope of the load v throughput graph flattens. They refer to the second point as the cliff; this is where packet losses may lead to a precipitous decline in throughput. Other authors use the term contention for knee-congestion.
In the Internet, most packet losses are due to congestion. This is not because congestion is especially bad (though it can be, at times), but rather that other types of losses (eg due to packet corruption) are insignificant by comparison.
We emphasize that the presence of congestion does not mean that a network has a shortage of bandwidth. Bulk-traffic senders (though not real-time senders) attempt to send as fast as possible, and congestion is simply the network’s feedback that the maximum transmission rate has been reached.
Congestion is a sign of a problem in real-time networks, which we will consider in 18 Quality of Service. In these networks losses due to congestion must generally be kept to an absolute minimum; one way to achieve this is to limit the acceptance of new connections unless sufficient resources are available.
1.8 Packets Again¶
Perhaps the core justification for packets, Baran’s concerns about node failure notwithstanding, is that the same link can carry, at different times, different packets representing traffic to different destinations and from different senders. Thus, packets are the key to supporting shared transmission lines; that is, they support the multiplexing of multiple communications channels over a single cable. The alternative of a separate physical line between every pair of machines grows prohibitively complex very quickly (though virtual circuits between every pair of machines in a datacenter are not uncommon; see 3.7 Virtual Circuits).
From this shared-medium perspective, an important packet feature is the maximum packet size, as this represents the maximum time a sender can send before other senders get a chance. The alternative of unbounded packet sizes would lead to prolonged network unavailability for everyone else if someone downloaded a large file in a single 1 Gigabit packet. Another drawback to large packets is that, if the packet is corrupted, the entire packet must be retransmitted; see 5.3.1 Error Rates and Packet Size.
When a router or switch receives a packet, it (generally) reads in the entire packet before looking at the header to decide to what next node to forward it. This is known as store-and-forward, and introduces a forwarding delay equal to the time needed to read in the entire packet. For individual packets this forwarding delay is hard to avoid (though some switches do implement cut-through switching to begin forwarding a packet before it has fully arrived), but if one is sending a long train of packets then by keeping multiple packets en route at the same time one can essentially eliminate the significance of the forwarding delay; see 5.3 Packet Size.
Total packet delay from sender to receiver is the sum of the following:
- Bandwidth delay, ie sending 1000 Bytes at 20 Bytes/millisecond will take 50 ms. This is a per-link delay.
- Propagation delay due to the speed of light. For example, if you start sending a packet right now on a 5000-km cable across the US with a propagation speed of 200 m/µsec (= 200 km/ms, about 2/3 the speed of light in vacuum), the first bit will not arrive at the destination until 25 ms later. The bandwidth delay then determines how much after that the entire packet will take to arrive.
- Store-and-forward delay, equal to the sum of the bandwidth delays out of each router along the path
- Queuing delay, or waiting in line at busy routers. At bad moments this can exceed 1 sec, though that is rare. Generally it is less than 10 ms and often is less than 1 ms. Queuing delay is the only delay component amenable to reduction through careful engineering.
See 5.1 Packet Delay for more details.
1.9 LANs and Ethernet¶
A local-area network, or LAN, is a system consisting of
- physical links that are, ultimately, serial lines
- common interfacing hardware connecting the hosts to the links
- protocols to make everything work together
We will explicitly assume that every LAN node is able to communicate with every other LAN node. Sometimes this will require the cooperation of intermediate nodes acting as switches.
Far and away the most common type of LAN is Ethernet, originally described in a 1976 paper by Metcalfe and Boggs [MB76]. Ethernet’s popularity is due to low cost more than anything else, though the primary reason Ethernet cost is low is that high demand has led to manufacturing economies of scale.
The original Ethernet had a bandwidth of 10 Mbps (megabits per second; we will use lower-case “b” for bits and upper-case “B” for bytes), though nowadays most Ethernet operates at 100 Mbps and gigabit (1000 Mbps) Ethernet (and faster) is widely used in server rooms. (By comparison, as of this writing the data transfer rate to a typical faster hard disk is about 1000 Mbps.) Wireless (“wi-fi”) LANs are gaining popularity, and in some settings have supplanted wired Ethernet to end-users.
Many early Ethernet installations were unswitched; each host simply tapped in to one long primary cable that wound through the building (or floor). In principle, two stations could then transmit at the same time, rendering the data unintelligible; this was called a collision. Ethernet has several design features intended to minimize the bandwidth wasted on collisions: stations, before transmitting, check to be sure the line is idle, they monitor the line while transmitting to detect collisions during the transmission, and, if a collision is detected, they execute a random backoff strategy to avoid an immediate recollision. See 2.1.2 The Slot Time and Collisions. While Ethernet collisions definitely reduce throughput, in the larger view they should perhaps be thought of as a part of a remarkably inexpensive shared-access mediation protocol.
In unswitched Ethernets every packet is received by every host and it is up to the network card in each host to determine if the arriving packet is addressed to that host. It is almost always possible to configure the card to forward all arriving packets to the attached host; this poses a security threat and “password sniffers” that surreptitiously collected passwords via such eavesdropping used to be common.
Due to both privacy and efficiency concerns, almost all Ethernets today are fully switched; this ensures that each packet is delivered only to the host to which it is addressed. One advantage of switching is that it effectively eliminates most Ethernet collisions; while in principle it replaces them with a queuing issue, in practice Ethernet switch queues so seldom fill up that they are almost invisible even to network managers (unlike IP router queues). Switching also prevents host-based eavesdropping, though arguably a better solution to this problem is encryption. Perhaps the more significant tradeoff with switches, historically, was that Once Upon A Time they were expensive and unreliable; tapping directly into a common cable was dirt cheap.
Ethernet addresses are six bytes long. Each Ethernet card (or network interface) is assigned a (supposedly) unique address at the time of manufacture; this address is burned into the card’s ROM and is called the card’s physical address or hardware address or MAC (Media Access Control) address. The first three bytes of the physical address have been assigned to the manufacturer; the subsequent three bytes are a serial number assigned by that manufacturer.
By comparison, IP addresses are assigned administratively by the local site. The basic advantage of having addresses in hardware is that hosts automatically know their own addresses on startup; no manual configuration or server query is necessary. It is not unusual for a site to have a large number of identically configured workstations, for which all network differences derive ultimately from each workstation’s unique Ethernet address.
The network interface continually monitors all arriving packets; if it sees any packet containing a destination address that matches its own physical address, it grabs the packet and forwards it to the attached CPU (via a CPU interrupt).
Ethernet also has a designated broadcast address. A host sending to the broadcast address has its packet received by every other host on the network; if a switch receives a broadcast packet on one port, it forwards the packet out every other port. This broadcast mechanism allows host A to contact host B when A does not yet know B’s physical address; typical broadcast queries have forms such as “Will the designated server please answer” or (from the ARP protocol) “will the host with the given IP address please tell me your physical address”.
Traffic addressed to a particular host – that is, not broadcast – is said to be unicast.
Because Ethernet addresses are assigned by the hardware, knowing an address does not provide any direct indication of where that address is located on the network. In switched Ethernet, the switches must thus have a forwarding-table record for each individual Ethernet address on the network; for extremely large networks this ultimately becomes unwieldy. Consider the analogous situation with postal addresses: Ethernet is somewhat like attempting to deliver mail using social-security numbers as addresses, where each postal worker is provided with a large catalog listing each person’s SSN together with their physical location. Real postal mail is, of course, addressed “hierarchically” using ever-more-precise specifiers: state, city, zipcode, street address, and name / room#. Ethernet, in other words, does not scale well to “large” sizes.
Switched Ethernet works quite well, however, for networks with up to 10,000-100,000 nodes. Forwarding tables with size in that range are straightforward to manage.
To forward packets correctly, switches must know where all active destination addresses in the LAN are located; Ethernet switches do this by a passive learning algorithm. (IP routers, by comparison, use “active” protocols.) Typically a host physical address is entered into a switch’s forwarding table when a packet from that host is first received; the switch notes the packet’s arrival interface and source address and assumes that the same interface is to be used to deliver packets back to that sender. If a given destination address has not yet been seen, and thus is not in the forwarding table, Ethernet switches still have the backup delivery option of forwarding to everyone, by treating the destination address like the broadcast address, and allowing the host Ethernet cards to sort it out. Since this broadcast-like process is not generally used for more than one packet (after that, the switches will have learned the correct forwarding-table entries), the risk of eavesdropping is minimal.
The ⟨host,interface⟩ forwarding table is often easier to think of as ⟨host,next_hop⟩, where the next_hop node is whatever switch or host is at the immediate other end of the link connecting to the given interface. In a fully switched network where each link connects only two interfaces, the two perspectives are equivalent.
1.10 IP - Internet Protocol¶
To solve the scaling problem with Ethernet, and to allow support for other types of LANs and point-to-point links as well, the Internet Protocol was developed. Perhaps the central issue in the design of IP was to support universal connectivity (everyone can connect to everyone else) in such a way as to allow scaling to enormous size (in 2013 there appear to be around ~109 nodes, although IP should work to 1010 nodes or more), without resulting in unmanageably large forwarding tables (currently the largest tables have about 300,000 entries.)
In the early days, IP networks were considered to be “internetworks” of basic networks (LANs); nowadays users generally ignore LANs and think of the Internet as one large (virtual) network.
To support universal connectivity, IP provides a global mechanism for addressing and routing, so that packets can actually be delivered from any host to any other host. IP addresses (for the most-common version 4, which we denote IPv4) are 4 bytes (32 bits), and are part of the IP header that generally follows the Ethernet header. The Ethernet header only stays with a packet for one hop; the IP header stays with the packet for its entire journey across the Internet.
An essential feature of IPv4 (and IPv6) addresses is that they can be divided into a “network” part (a prefix) and a “host” part (the remainder). The “legacy” mechanism for designating the IPv4 network and host address portions was to make the division according to the first few bits:
| first few bits | first byte | network bits | host bits | name | application |
|---|---|---|---|---|---|
| 0 | 0-127 | 8 | 24 | class A | a few very large networks |
| 10 | 128-191 | 16 | 16 | class B | institution-sized networks |
| 110 | 192-223 | 24 | 8 | class C | sized for smaller entities |
For example, the original IP address allocation for Loyola University Chicago was 147.126.0.0, a class B. In binary, 147 is 10010011. The network/host division point is not carried within the IP header; in fact, nowadays the division into network and host is dynamic, and can be made at different positions in the address at different levels of the network.
IP addresses, unlike Ethernet addresses, are administratively assigned. You would get your Class B network portion, say, from the Internet Assigned Numbers Authority, or IANA, and then you would in turn assign the host portion in a way that was appropriate for your local site. As a result of this administrative assignment, an IP address usually serves not just as an endpoint identifier but also as a locator, containing embedded location information.
The Class A/B/C definition above was spelled out in 1981 in RFC 791, which introduced IP. Class D was added in 1986 by RFC 988; class D addresses must begin with the bits 1110. These addresses are for multicast, that is, sending an IP packet to every member of a set of recipients (ideally without actually transmitting it more than once on any one link).
The network portion of an IP address is sometimes called the network number or network address or network prefix; it is commonly denoted by setting the host bits to zero and ending the resultant address with a slash followed by the number of network bits in the address: eg 12.0.0.0/8 or 147.126.0.0/16. Note that 12.0.0.0/8 and 12.0.0.0/9 represent different things; in the latter, the second byte of any host address extending the network address is constrained to begin with a 0-bit. An anonymous block of IP addresses might be referred to only by the slash and following digit, eg “we need a /22 block to accommodate all our customers”.
All hosts with the same network address (same network bits) must be located together on the same LAN; as we shall see below, if two hosts share the same network address then they will assume they can reach each other directly via the underlying LAN, and if they cannot then connectivity fails. A consequence of this rule is that outside of the site only the network bits need to be looked at to route a packet to the site.
IP routers use datagram forwarding, described in 1.4 Datagram Forwarding above, to deliver packets, but the “destination” values listed in their forwarding tables are network prefixes – representing entire LANs – instead of individual hosts. The goal of IP forwarding, then, becomes delivery to the correct LAN; a separate process is used to deliver to the final host once the final LAN has been reached.
The entire point, in fact, of having a network/host division within IP addresses is so that routers need to list only the network prefixes of the destination addresses in their IP forwarding tables. This strategy is the key to IP scalability: it saves large amounts of forwarding-table space, it saves time as smaller tables allow faster lookup, and it saves the bandwidth that would be needed for routers to keep track of individual addresses. To get an idea of the forwarding-table space savings, there are currently (2013) around a billion hosts on the Internet, but only 300,000 or so networks listed in top-level forwarding tables. When network prefixes are used as forwarding-table destinations, matching an actual packet address to a forwarding-table entry is no longer a matter of simple equality comparison; routers must compare appropriate prefixes.
IP forwarding tables are sometimes also referred to as “routing tables”; in this book, however, we make at least a token effort to use “forwarding” to refer to the packet forwarding process, and “routing” to refer to mechanisms by which the forwarding tables are maintained and updated. (If we were to be completely consistent here, we would use the term “forwarding loop” rather than “routing loop”.)
We will refer to the Internet backbone as those IP routers that specialize in large-scale routing on the commercial Internet, and which generally have forwarding-table entries covering all public IP addresses; note that this is essentially a business definition rather than a technical one. We can revise the table-size claim of the previous paragraph to state that, while there are many private IP networks, there are about 300,000 visible to the backbone. A forwarding table of 300,000 entries is quite feasible; a table a hundred times larger is not, let alone a thousand times larger.
One can think of the network-prefix bits as analogous to the “zip code” on postal mail, and the host bits as analogous to the street address. Alternatively, one can think of the network bits as like the area code of a phone number, and the host bits as like the rest of the digits. Newer protocols that support different net/host division points at different places in the network – sometimes called hierarchical routing – allow support for addressing schemes that correspond to, say, zip/street/user, or areacode/exchange/subscriber.
Each individual LAN technology has a maximum packet size it supports; for example, Ethernet has a maximum packet size of about 1500 bytes but the once-competing Token Ring had a maximum of 4 KB. Today the world has largely standardized on Ethernet and almost entirely standardized on Ethernet packet-size limits, but this was not the case when IP was introduced and there was real concern that two hosts on separate large-packet networks might try to exchange packets too large for some small-packet intermediate network to carry.
Therefore, in addition to routing and addressing, the decision was made that IP must also support fragmentation: the division of large packets into multiple smaller ones (in other contexts this may also be called segmentation). The IP approach is not very efficient, and IP hosts go to considerable lengths to avoid fragmentation. IP does require that packets of up to 576 bytes be supported, and so a common legacy strategy was for a host to limit a packet to at most 512 user-data bytes whenever the packet was to be sent via a router; packets addressed to another host on the same LAN could of course use a larger packet size. Despite its limited use, however, fragmentation is essential conceptually, in order for IP to be able to support large packets without knowing anything about the intervening networks.
IP is a best effort system; there are no IP-layer acknowledgments or retransmissions. We ship the packet off, and hope it gets there. Most of the time, it does.
Architecturally, this best-effort model represents what is known as connectionless networking: the IP layer does not maintain information about endpoint-to-endpoint connections, and simply forwards packets like a giant LAN. Responsibility for creating and maintaining connections is left for the next layer up, the TCP layer. Connectionless networking is not the only way to do things: the alternative could have been some form connection-oriented internetworking, in which routers do maintain state information about individual connections. Later, in 3.7 Virtual Circuits, we will examine how virtual-circuit networking can be used to implement a connection-oriented approach; virtual-circuit switching is the primary alternative to datagram switching.
Connectionless (IP-style) and connection-oriented networking each have advantages. Connectionless networking is conceptually more reliable: if routers do not hold connection state, then they cannot lose connection state. The path taken by the packets in some higher-level connection can easily be dynamically rerouted. Finally, connectionless networking makes it hard for providers to bill by the connection; once upon a time (in the era of dollar-a-minute phone calls) this was a source of mild astonishment to many new users. The primary advantage of connection-oriented networking, however, is that the routers are then much better positioned to accept reservations and to make quality-of-service guarantees. This remains something of a sore point in the current Internet: if you want to use Voice-over-IP, or VoIP, telephones, or if you want to engage in video conferencing, your packets will be treated by the Internet core just the same as if they were low-priority file transfers. There is no “priority service” option.
Perhaps the most common form of IP packet loss is router queue overflows, representing network congestion. Packet losses due to packet corruption are rare (eg less than one in 104; perhaps much less). But in a connectionless world a large number of hosts can simultaneously decide to send traffic through one router, in which case queue overflows are hard to avoid.
Now let us look at a simple example of how IP routing (or forwarding) works. We will assume that all network nodes are either hosts – user machines, with a single network connection – or routers, which do packet-forwarding only. Routers are not directly visible to users, and always have at least two different network interfaces representing different networks that the router is connecting. (Machines can be both hosts and routers, but this introduces complications.)
Suppose A is the sending host, sending a packet to a destination host D. The IP header of the packet will contain D’s IP address in the “destination address” field (it will also contain A’s own address as the “source address”). The first step is for A to determine whether D is on the same LAN as itself or not. This is done by looking at the network part of the destination address, which we will denote by Dnet. If this net address is the same as A’s (that is, if it is equal numerically to Anet), then A figures D is on the same LAN as itself, and can use direct LAN delivery . It looks up the appropriate physical address for D (probably with the ARP protocol, 7.7 Address Resolution Protocol: ARP), attaches a LAN header to the packet in front of the IP header, and sends the packet straight to D via the LAN.
If, however, Anet and Dnet do not match, then A looks up a router to use. Most ordinary hosts use only one router for all non-local packet deliveries, making this choice very simple. A then forwards the packet to the router, again using direct delivery over the LAN. The IP destination address in the packet remains D in this case, although the LAN destination address will be that of the router.
When the router receives the packet, it strips off the LAN header but leaves the IP header with the IP destination address. It extracts the destination D, and then looks at Dnet. The router first checks to see if any of its network interfaces are on the same LAN as D; recall that the router connects to at least one additional network besides the one for A. If the answer is yes, then the router uses direct LAN delivery to the destination, as above. If, on the other hand, Dnet is not a LAN to which the router is connected directly, then the router consults its internal forwarding table. This consists of a list of networks each with an associated next_hop address. These ⟨net,next_hop⟩ tables compare with switched-Ethernet’s ⟨host,next_hop⟩ tables; the former type will be smaller because there are many fewer nets than hosts. The next_hop addresses in the table are chosen so that the router can always reach them via direct LAN delivery via one of its interfaces; generally they are other routers. The router looks up Dnet in the table, finds the next_hop address, and uses direct LAN delivery to get the packet to that next_hop machine. The packet’s IP header remains essentially unchanged, although the router most likely attaches an entirely new LAN header.
The packet continues being forwarded like this, from router to router, until it finally arrives at a router that is connected to Dnet; it is then delivered by that final router directly to D, using the LAN.
To make this concrete, consider the following diagram:

With Ethernet-style forwarding, R2 would have to maintain entries for each of A,B,C,D,E,F. With IP forwarding, R2 has just two entries to maintain in its forwarding table: 200.0.0/24 and 200.0.1/24. If A sends to D, at 200.0.1.37, it puts this address into the IP header, notes that 200.0.0 ≠ 200.0.1, and thus concludes D is not a local delivery. A therefore sends the packet to its router R1, using LAN delivery. R1 looks up the destination network 200.0.1 in its forwarding table and forwards the packet to R2, which in turn forwards it to R3. R3 now sees that it is connected directly to the destination network 200.0.1, and delivers the packet via the LAN to D, by looking up D’s physical address.
In this diagram, IP addresses for the ends of the R1–R2 and R2–R3 links are not shown. They could be assigned global IP addresses, but they could also use “private” IP addresses. Assuming these links are point-to-point links, they might not actually need IP addresses at all; we return to this in 7.10 Unnumbered Interfaces.
IP routers at non-backbone sites generally know all locally assigned network prefixes, eg 200.0.0/24 and 200.0.1/24 above. If a destination does not match any locally assigned network prefix, the packet needs to be routed out into the Internet at large; for typical non-backbone sites this almost always this means the packet is sent to the ISP that provides Internet connectivity. Generally the local routers will contain a catchall default entry covering all nonlocal networks; this means that the router needs an explicit entry only for locally assigned networks. This greatly reduces the forwarding-table size.
For most purposes, the Internet can be seen as a combination of end-user LANs together with point-to-point links joining these LANs to the backbone, point-to-point links also tie the backbone together. Both LANs and point-to-point links appear in the diagram above.
Just how routers build their ⟨destnet,next_hop⟩ forwarding tables is a major topic itself, which we cover in 9 Routing-Update Algorithms. Unlike Ethernet, IP routers do not have a “broadcast” delivery mechanism as a fallback, so the tables must be constructed in advance. (There is a limited form of IP broadcast, but it is basically intended for reaching the local LAN only, and does not help at all with delivery in the event that the network is unknown.)
Most forwarding-table-construction algorithms used on a set of routers under common management fall into either the distance-vector or the link-state category. In the distance-vector approach, often used at smaller sites, routers exchange information with their immediately neighboring routers; tables are built up this way through a sequence of such periodic exchanges. In the link-state approach, routers rapidly propagate information about the state of each link; all routers in the organization receive this link-state information and each one uses it to build and maintain a map of the entire network. The forwarding table is then constructed (sometimes on demand) from this map.
Unrelated organizations exchange information through the Border Gateway Protocol, BGP (10 Large-Scale IP Routing), which allows for a fusion of technical information (which sites are reachable at all, and through where) with “policy” information representing legal or commercial agreements: which outside routers are “preferred”, whose traffic we will carry even if it isn’t to one of our customers, etc.
Internet 2 is a consortium of research sites with very-high-bandwidth internal interconnections. Before Internet 2, Loyola’s largest router table consisted of maybe a dozen internal routes, plus one “default” route to the outside Internet. After Internet 2, the default route still pointed to the commercial Internet, but the master forwarding table now had to have an entry for every Internet-2 site so this traffic would take the Internet-2 path. See 7 IP version 4, exercise 5.
As of the end of January 2011, the IANA has run out of Class-A blocks to allocate to the five regional registries, which are
- ARIN – North America
- RIPE – Europe, the Middle East and parts of Asia
- APNIC – East Asia and the Pacific
- AfriNIC – most of Africa
- LACNIC – Central and South America
There is a table at http://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xmlof IANA assignments of /8 blocks; examination of the table shows all /8 blocks have now been allocated. A few months after the IANA ran out, Microsoft purchased 666,624 IP addresses (2604 Class-C blocks) in a Nortel bankruptcy auction for $7.5 million. By a year later, IP-address prices appear to have retreated only slightly.
Hopefully, this turn of events will accelerate implementation of IPv6, which has 128-bit addresses.
1.11 DNS¶
IP addresses are hard to remember (nearly impossible in IPv6). The domain name system, or DNS, comes to the rescue by creating a way to convert hierarchical text names to IP addresses. Thus, for example, one can type www.luc.edu instead of 147.126.1.230. Virtually all Internet software uses the same basic library calls to convert DNS names to actual addresses.
One thing DNS makes possible is changing a website’s IP address while leaving the name alone. This allows moving a site to a new provider, for example, without requiring users to learn anything new. It is also possible to have several different DNS names resolve to the same IP address, and – through some modest trickery – have the http (web) server at that IP address handle the different DNS names as completely different websites.
DNS is hierarchical and distributed; indeed, it is the classic example of a widely distributed database. In looking up www.cs.luc.edu three different DNS servers may be queried: for cs.luc.edu, for luc.edu, and for .edu. Searching a hierarchy can be cumbersome, so DNS search results are normally cached locally. If a name is not found in the cache, the lookup may take a couple seconds. The DNS hierarchy need have nothing to do with the IP-address hierarchy.
Besides address lookups, DNS also supports a few other kinds of searches. The best known is probably reverse DNS, which takes an IP address and returns a name. This is slightly complicated by the fact that one IP address may be associated with multiple DNS names, so DNS must either return a list, or return one name that has been designated the canonical name.
1.12 Transport¶
Think about what types of communications one might want over the Internet:
- Interactive communications such as via ssh or telnet, with long idle times between short bursts
- Bulk file transfers
- Request/reply operations, eg to query a database or to make DNS requests
- Real-time voice traffic, at (without compression) 8KB/sec, with constraints on the variation in delivery time (known as jitter; see 18.11.3 RTP Control Protocol for a specific numeric interpretation)
- Real-time video traffic. Even with substantial compression, video generally requires much more bandwidth than voice
While separate protocols might be used for each of these, the Internet has standardized on the Transmission Control Protocol, or TCP, for the first three (though there are periodic calls for a new protocol addressing the third item above), and TCP is sometimes pressed into service for the last two. TCP is thus the most common “transport” layer for application data.
The IP layer is not well-suited to transport. IP routing is a “best-effort” mechanism, which means packets can and do get lost sometimes. Data that does arrive can arrive out of order. The sender has to manage division into packets; that is, buffering. Finally, IP only supports sending to a specific host; normally, one wants to send to a given application running on that host. Email and web traffic, or two different web sessions, should not be commingled!
TCP extends IP with the following features:
- reliability: TCP numbers each packet, and keeps track of which are lost and retransmits them after a timeout, and holds early-arriving out-of-order packets for delivery at the correct time. Every arriving data packet is acknowledged by the receiver; timeout and retransmission occurs when an acknowledgment isn’t received by the sender within a given time.
- connection-orientation: Once a TCP connection is made, an application sends data simply by writing to that connection. No further application-level addressing is needed.
- stream-orientation: The application can write 1 byte at a time, or 100KB at a time; TCP will buffer and/or divide up the data into appropriate sized packets.
- port numbers: these provide a way to specify the receiving application for the data, and also to identify the sending application.
- throughput management: TCP attempts to maximize throughput, while at the same time not contributing unnecessarily to network congestion.
TCP endpoints are of the form ⟨host,port⟩; these pairs are known as socket addresses, or sometimes as just sockets though the latter refers more properly to the operating-system objects that receive the data sent to the socket addresses. Servers (or, more precisely, server applications) listen for connections to sockets they have opened; clients initiate those connections. When you enter a host name in a web browser, it opens a TCP connection to the server’s port 80 (the standard web-traffic port), that is, to the server socket with socket-address ⟨server,80⟩. If you have several browser tabs open, each might connect to the same server socket, but the connections are distinguishable by virtue of using separate ports (and thus having separate socket addresses) on the client end (that is, your end).
A busy server may have thousands of connections to its port 80 (the web port) and hundreds of connections to port 25 (the email port). Web and email traffic are kept separate by virtue of the different ports used. All those clients to the same port, though, are kept separate because each comes from a unique ⟨host,port⟩ pair. A TCP connection is determined by the ⟨host,port⟩ socket address at each end; traffic on different connections does not intermingle. That is, there may be multiple independent connections to ⟨www.luc.edu,80⟩. This is somewhat analogous to certain business telephone numbers of the “operators are standing by” type, which support multiple callers at the same time to the same number. Each call is answered by a different operator (corresponding to a different cpu process), and different calls do not “overhear” each other.
TCP uses the sliding-windows algorithm, 6 Abstract Sliding Windows, to keep multiple packets en route at any one time. The window size represents the number of packets simultaneously en route; if the window size is 10, for example, then at any one time 10 packets are out there (perhaps 5 data packets and 5 returning acknowledgments). As each acknowledgment arrives, the window “slides forward” and the data packet 10 packets ahead is sent. For example, consider the moment when the ten packets 20-29 are in transit. When ACK[20] is received, Data[30] is sent, and so now packets 21-30 are in transit. When ACK[21] is received, Data[31] is sent, so packets 22-31 are in transit.
Sliding windows minimizes the effect of store-and-forward delays, and propagation delays, as these then only count once for the entire windowful and not once per packet. Sliding windows also provides an automatic, if partial, brake on congestion: the queue at any switch or router along the way cannot exceed the window size. In this it compares favorably with constant-rate transmission, which, if the available bandwidth falls below the transmission rate, always leads to a significant percentage of dropped packets. Of course, if the window size is too large, a sliding-windows sender may also experience dropped packets.
The ideal window size, at least from a throughput perspective, is such that it takes one round-trip time to send an entire window, so that the next ACK will always be arriving just as the sender has finished transmitting the window. Determining this ideal size, however, is difficult; for one thing, the ideal size varies with network load. As a result, TCP approximates the ideal size. The most common TCP strategy – that of so-called TCP Reno – is that the window size is slowly raised until packet loss occurs, which TCP takes as a sign that it has reached the limit of available network resources. At that point the window size is reduced to half its previous value, and the slow climb resumes. The effect is a “sawtooth” graph of window size with time, which oscillates (more or less) around the “optimal” window size. For an idealized sawtooth graph, see 13.1.1 The Steady State; for some “real” (simulation-created) sawtooth graphs see 16.4.1 Some TCP Reno cwnd graphs.
While this window-size-optimization strategy has its roots in attempting to maximize the available bandwidth, it also has the effect of greatly limiting the number of packet-loss events. As a result, TCP has come to be the Internet protocol charged with reducing (or at least managing) congestion on the Internet, and – relatedly – with ensuring fairness of bandwidth allocations to competing connections. Core Internet routers – at least in the classical case – essentially have no role in enforcing congestion or fairness restrictions at all. The Internet, in other words, places responsibility for congestion avoidance cooperatively into the hands of end users. While “cheating” is possible, this cooperative approach has worked remarkably well.
While TCP is ubiquitous, the real-time performance of TCP is not always consistent: if a packet is lost, the receiving TCP host will not turn over anything further to the receiving application until the lost packet has been retransmitted successfully; this is often called head-of-line blocking. This is a serious problem for sound and video applications, which can discretely handle modest losses but which have much more difficulty with sudden large delays. A few lost packets ideally should mean just a few brief voice dropouts (pretty common on cell phones) or flicker/snow on the video screen (or just reuse of the previous frame); both of these are better than pausing completely.
The basic alternative to TCP is known as UDP, for User Datagram Protocol. UDP, like TCP, provides port numbers to support delivery to multiple endpoints within the receiving host, in effect to a specific process on the host. As with TCP, a UDP socket consists of a ⟨host,port⟩ pair. UDP also includes, like TCP, a checksum over the data. However, UDP omits the other TCP features: there is no connection setup, no lost-packet detection, no automatic timeout/retransmission, and the application must manage its own packetization.
The Real-time Transport Protocol, or RTP, sits above UDP and adds some additional support for voice and video applications.
1.13 Firewalls¶
One problem with having a program on your machine listening on an open TCP port is that someone may connect and then, using some flaw in the software on your end, do something malicious to your machine. Damage can range from the unintended downloading of personal data to compromise and takeover of your entire machine, making it a distributor of viruses and worms or a steppingstone in later break-ins of other machines.
A strategy known as buffer overflow has been the basis for a great many total-compromise attacks. The idea is to identify a point in a server program where it fills a memory buffer with network-supplied data without careful length checking; almost any call to the C library function gets(buf) will suffice. The attacker then crafts an oversized input string which, when read by the server and stored in memory, overflows the buffer and overwrites subsequent portions of memory, typically containing the stack-frame pointers. The usual goal is to arrange things so that when the server reaches the end of the currently executing function, control is returned not to the calling function but instead to the attacker’s own payload code located within the string.
A firewall is a program to block connections deemed potentially risky, eg those originating from outside the site. Generally ordinary workstations do not ever need to accept connections from the Internet; client machines instead initiate connections to (better-protected) servers. So blocking incoming connections works pretty well; when necessary (eg for games) certain ports can be selectively unblocked.
The original firewalls were routers. Incoming traffic to servers was often blocked unless it was sent to one of a modest number of “open” ports; for non-servers, typically all inbound connections were blocked. This allowed internal machines to operate reasonably safely, though being unable to accept incoming connections is sometimes inconvenient. Nowadays per-machine firewalls – in addition to router-based firewalls – are common: you can configure your machine not to accept inbound connections to most (or all) ports regardless of whether software on your machine requests such a connection. Outbound connections can, in many cases, also be prevented.
1.14 Network Address Translation¶
A related way of providing firewall protection for ordinary machines is Network Address Translation, or NAT. This technique also conserves IP addresses. Instead of assigning each host at a site a “real” IP address, just one address is assigned to a border router. Internal machines get “internal” IP addresses, typically of the form or 192.168.x.y or 10.x.y.z (addresses beginning with 192.168.0.0/16 or with 10.0.0.0/8 cannot be used on the Internet). Inbound connections to the internal machines are banned, as with some firewalls. When an internal machine wants to connect to the outside, the NAT router intercepts the connection, allocates a new port, and forwards the connection on as if it came from that new port and its own IP address. The remote machine responds, and the NAT router remembers the connection and forwards data to the correct internal host, rewriting the address and port fields of the incoming packets. Done properly, NAT improves the security of a site. It also allows multiple machines to share a single IP address, and so is popular with home users who have a single broadband connection but who wish to use multiple computers. A typical NAT router sold for residential or small-office use is commonly simply called a “router”, or (somewhat more precisely) a “residential gateway”.
Suppose the NAT router is NR, and internal hosts A and B each connect from port 3000 to port 80 on external hosts C and D, respectively. Here is what NR’s NAT table might look like. No column for NR’s IP address is given, as it is fixed.
| remote host | remote port | outside source port | inside host | inside port |
|---|---|---|---|---|
| C | 80 | 3000 | A | 3000 |
| D | 80 | 3000 | B | 3000 |
A packet to C from ⟨A,3000⟩ would be rewritten by NR so that the source was ⟨NR,3000⟩. A packet from ⟨C,80⟩ addressed to ⟨NR,3000⟩ would be rewritten and forwarded to ⟨A,3000⟩. Similarly, a packet from ⟨D,80⟩ addressed to ⟨NR,3000⟩ would be rewritten and forwarded to ⟨B,3000⟩; the NAT table takes into account the sending socket address as well as the destination.
Now suppose B opens a connection to ⟨C,80⟩, also from inside port 3000. This time NR must remap the port number, because that is the only way to distinguish between packets from ⟨C,80⟩ to A and to B. The new table is
| remote host | remote port | outside source port | inside host | inside port |
|---|---|---|---|---|
| C | 80 | 3000 | A | 3000 |
| D | 80 | 3000 | B | 3000 |
| C | 80 | 3001 | B | 3000 |
Typically NR would not create TCP connections between itself and ⟨C,80⟩ and ⟨D,80⟩; the NAT table does forwarding but the endpoints of the connection are still at the inside hosts. However, NR might very well monitor the TCP connections to know when they have closed, and so can be removed from the table.
It is common for Voice-over-IP (VoIP) telephony using the SIP protocol (RFC 3261) to prefer to use UDP port 5060 at both ends. If a VoIP server is outside the NAT router (which must be the case as the server must generally be publicly visible) and a telephone is inside, likely port 5060 will pass through without remapping, though the telephone will have to initiate the connection. But if there are two phones inside, one of them will appear to be connecting to the server from an alternative port.
VoIP systems run into a much more serious problem with NAT, however. A call ultimately between two phones is typically first negotiated between the phones’ respective VoIP servers. Once the call is set up, the servers would prefer to step out of the loop, and have the phones exchange voice packets directly. The SIP protocol was designed to handle this by having each phone report to its respective server the UDP socket (⟨IP address,port⟩ pair) it intends to use for the voice exchange; the servers then report these phone sockets to each other, and from there to the opposite phones. This socket information is rendered incorrect by NAT, however, certainly the IP address and quite likely the port as well. If only one of the phones is behind a NAT firewall, it can initiate the voice connection to the other phone, but the other phone will see the voice packets arriving from a different socket than promised and will likely not recognize them as part of the call. If both phones are behind NAT firewalls, they will not be able to connect to one another at all. The common solution is for the VoIP server of a phone behind a NAT firewall to remain in the communications path, forwarding packets to its hidden partner.
If a site wants to make it possible to allow connections to hosts behind a NAT router or other firewall, one option is tunneling. This is the creation of a “virtual LAN link” that runs on top of a TCP connection between the end user and one of the site’s servers; the end user can thus appear to be on one of the organization’s internal LANs; see 3.1 Virtual Private Network. Another option is to “open up” a specific port: in essence, a static NAT-table entry is made connecting a specific port on the NAT router to a specific internal host and port (usually the same port). For example, all UDP packets to port 5060 on the NAT router might be forwarded to port 5060 on internal host A, even in the absence of any prior packet exchange.
NAT routers work very well when the communications model is of client-side TCP connections, originating from the inside and with public outside servers as destination. The NAT model works less well for “peer-to-peer” networking, where your computer and a friend’s, each behind a different NAT router, wish to establish a connection. NAT routers also often have trouble with UDP protocols, due to the tendency for such protocols to have the public server reply from a different port than the one originally contacted. For example, if host A behind a NAT router attempts to use TFTP (11.3 Trivial File Transport Protocol, TFTP), and sends a packet to port 69 of public server C, then C is likely to reply from some new port, say 3000, and this reply is likely to be dropped by the NAT router as there will be no entry there yet for traffic from ⟨C,3000⟩.
1.15 IETF and OSI¶
The Internet protocols discussed above are defined by the Internet Engineering Task Force, or IETF (under the aegis of the Internet Architecture Board, or IAB, in turn under the aegis of the Internet Society, ISOC). The IETF publishes “Request For Comment” or RFC documents that contain all the formal Internet standards; these are available at http://www.ietf.org/rfc.html (note that, by the time a document appears here, the actual comment-requesting period is generally long since closed). The five-layer model is closely associated with the IETF, though is not an official standard.
RFC standards sometimes allow modest flexibility. With this in mind, RFC 2119 declares official understandings for the words MUST and SHOULD. A feature labeled with MUST is “an absolute requirement for the specification”, while the term SHOULD is used when
there may exist valid reasons in particular circumstances to ignore a particular item, but the full implications must be understood and carefully weighed before choosing a different course.
The original ARPANET network was developed by the US government’s Defense Advanced Research Projects Agency, or DARPA; it went online in 1969. The National Science Foundation began NSFNet in 1986; this largely replaced ARPANET. In 1991, operation of the NSFNet backbone was turned over to ANSNet, a private corporation. The ISOC was founded in 1992 as the NSF continued to retreat from the networking business.
- Hallmarks of the IETF design approach were David Clark’s declaration
- We reject: kings, presidents and voting.We believe in: rough consensus and running code.
- and RFC Editor Jon Postel‘s aphorism
- Be liberal in what you accept, and conservative in what you send.
There is a persistent – though false – notion that the distributed-routing architecture of IP was due to a US Department of Defense mandate that the original ARPAnet be able to survive a nuclear attack. In fact, the developers of IP seemed unconcerned with this. However, Paul Baran did write, in his 1962 paper outlining the concept of packet switching, that
If [the number of stations] is made sufficiently large, it can be shown that highly survivable system structures can be built – even in the thermonuclear era.
In 1977 the International Organization for Standardization, or ISO, founded the Open Systems Interconnection project, or OSI, a process for creation of new network standards. OSI represented an attempt at the creation of networking standards independent of any individual government.
The OSI project is today perhaps best known for its seven-layer networking model: between Transport and Application were inserted the Session and Presentation layers. The Session layer was to handle “sessions” between applications (including the graceful closing of Transport-layer connections, something included in TCP, and the re-establishment of “broken” Transport-layer connections, which TCP could sorely use), and the Presentation layer was to handle things like defining universal data formats (eg for binary numeric data, or for non-ASCII character sets), and eventually came to include compression and encryption as well. However, most of the features at this level have ended up generally being implemented in the Application layer of the IETF model with no inconvenience. Indeed, there are few examples in the TCP/IP world of data format, compression or encryption being handled as a “sublayer” of the application, in which the sublayer is responsible for connections to the Transport layer (SSL/TLS might be an example for encryption; applications read and write data directly to the SSL endpoint). Instead, applications usually read and write data directly from/to the TCP layer, and then invoke libraries to handle things like data conversion, compression and encryption.
OSI has its own version of IP and TCP. The IP equivalent is CLNP, the ConnectionLess Network Protocol, although OSI also defines a connection-oriented protocol CMNS. The TCP equivalent is TP4; OSI also defines TP0 through TP3 but those are for connection-oriented networks.
It seems clear that the primary reasons the OSI protocols failed in the marketplace were their ponderous bureaucracy for protocol management, their principle that protocols be completed before implementation began, and their insistence on rigid adherence to the specifications to the point of non-interoperability. In contrast, the IETF had (and still has) a “two working implementations” rule for a protocol to become a “Draft Standard”. From RFC 2026:
- A specification from which at least two independent and interoperable implementations from different code bases have been developed, and for which sufficient successful operational experience has been obtained, may be elevated to the “Draft Standard” level. [emphasis added]
This rule has often facilitated the discovery of protocol design weaknesses early enough that the problems could be fixed. The OSI approach is a striking failure for the “waterfall” design model, when competing with the IETF’s cyclic “prototyping” model. However, it is worth noting that the IETF has similarly been unable to keep up with rapid changes in html, particularly at the browser end; the OSI mistakes were mostly evident only in retrospect.
Trying to fit protocols into specific layers is often both futile and irrelevant. By one perspective, the Real-Time Protocol RTP lives at the Transport layer, but just above the UDP layer; others have put RTP into the Application layer. Parts of the RTP protocol resemble the Session and Presentation layers. A key component of the IP protocol is the set of various router-update protocols; some of these freely use higher-level layers. Similarly, tunneling might be considered to be a Link-layer protocol, but tunnels are often created and maintained at the Application layer.
- A sometimes-more-successful approach to understanding “layers” is to view them instead as parts of a protocol graph. Thus we can have both of
- IP ⟵UDP ⟵RTPIP ⟵TCP
- (with the arrows pointing downwards in the graph) and
- Ethernet ⟵IPEthernet ⟵ARP ⟵IPATM ⟵IP
1.16 Berkeley Unix¶
Though not officially tied to the IETF, the Berkeley Unix releases became de facto reference implementations for most of the TCP/IP protocols. 4.1BSD (BSD for Berkeley Software Distribution) was released in 1981, 4.2BSD in 1983, 4.3BSD in 1986, 4.3BSD-Tahoe in 1988, 4.3BSD-Reno in 1990, and 4.4BSD in 1994. Descendants today include FreeBSD, OpenBSD and NetBSD. The TCP implementations TCP Tahoe and TCP Reno (13 TCP Reno and Congestion Management) took their names from the corresponding 4.3BSD releases.
1.17 Epilog¶
This completes our tour of the basics. In the remaining chapters we will expand on the material here.
1.18 Exercises¶
1. Give forwarding tables for each of the switches S1-S4 in the following network with destinations A, B, C, D. For the next_hop column, give the neighbor on the appropriate link rather than the interface number.
A B C
│ │ │
S1────────S2────────S3
│
│
S4───D
2. Give forwarding tables for each of the switches S1-S4 in the following network with destinations A, B, C, D. Again, use the neighbor form of next_hop rather than the interface form. Try to keep the route to each destination as short as possible. What decision has to be made in this exercise that did not arise in the preceding exercise?
A───S1──────S2───B
│ │
│ │
D───S4──────S3───C
3. Consider the following arrangement of switches and destinations. Give forwarding tables (in neighbor form) for S1-S4 that include default forwarding entries; the default entries should point toward S5. Eliminate all table entries that are implied by the default entry (that is, if the default entry is to S3, eliminate all other entries for which the next hop is S3).
A───S1
│ D
│ │
C───S3────────S4─────────S5
│ │
│ E
B───S2
4. Four switches are arranged as below. The destinations are S1 through S4 themselves.
S1──────S2
│ │
│ │
S4──────S3
- 5. Suppose we have switches S1 through S4; the forwarding-table destinations are the switches themselves. The tables for S2 and S3 are as below, where the next_hop value is specified in neighbor form:
- S2: ⟨S1,S1⟩ ⟨S3,S3⟩ ⟨S4,S3⟩S3: ⟨S1,S2⟩ ⟨S2,S2⟩ ⟨S4,S4⟩
From the above we can conclude that S2 must be directly connected to both S1 and S3 as its table lists them as next_hops; similarly, S3 must be directly connected to S2 and S4.
S3: ⟨S1,S4⟩ ⟨S2,S2⟩ ⟨S4,S4⟩
While the table for S4 is not given, you may assume that forwarding does work correctly. However, you should not assume that paths are the shortest possible; in particular, you should not assume that each switch will always reach its directly connected neighbors by using the direct connection.
6. (a) Suppose a network is as follows, with the only path from A to C passing through B:
... ──A────B────C── ...
Explain why a single routing loop cannot include both A and C.
(b). Suppose a routing loop follows the path A──S1──S2── ... ──Sn──A, where none of the Si are equal to A. Show that all the Si must be distinct. (A corollary of this is that any routing loop created by datagram-forwarding either involves forwarding back and forth between a pair of adjacent switches, or else involves an actual graph cycle in the network topology; linear loops of length greater than 1 are impossible.)
7. Consider the following arrangement of switches:
S1─────S4─────S10──A──E
│ │
│ │
S2─────S5─────S11──B
│ │
│ │
S3─────S6─────S12──C──D──F
Suppose S1-S6 have the forwarding tables below. For each destination A,B,C,D,E,F, suppose a packet is sent to the destination from S1. Give the switches it passes through, including the initial switch S1, up until the final switch S10-S12.
S1: (A,S4), (B,S2), (C,S4), (D,S2), (E,S2), (F,S4)
S2: (A,S5), (B,S5), (D,S5), (E,S3), (F,S3)
S3: (B,S6), (C,S2), (E,S6), (F,S6)
S4: (A,S10), (C,S5), (E,S10), (F,S5)
S5: (A,S6), (B,S11), (C,S6), (D,S6), (E,S4), (F,S2)
S6: (A,S3), (B,S12), (C,S12), (D,S12), (E,S5), (F,S12)
8. In the previous exercise, the routes taken by packets A-D are reasonably direct, but the routes for E and F are rather circuitous.
Some routing applications assign weights to different links, and attempt to choose a path with the lowest total link weight.
Hint: you can do this by assigning a weight of 1 to all links except to one or two “bad” links; the “bad” links get a weight of 10. In each of (a) and (b) above, the route taken will be the route that avoids all the “bad” links. You must treat (a) entirely differently from (b); there is no assignment of weights that can account for both routes.
9. Suppose we have the following three Class C IP networks, joined by routers R1–R4. Give the forwarding table for each router. For networks directly connected to a router (eg 200.0.1/24 and R1), include the network in the table but list the next hop as direct.
R1── 200.0.1/24
│
│
│
R4──────────R2── 200.0.2/24
│
│
│
R3── 200.0.3/24